GCP VisionAPIを使ってreCAPTCHA画像認証を突破する
- 2020-02-05

Google Cloud PlatformではVisionAPIという人工知能サービスを利用できます。
VisionAPIは画像から人や物を検出したり手書き文字を書き起こしたりできます。APIに任意の画像を送ると分析された結果を取得できます。
VisionAPIはGCP無料枠の対象になっているので、制限はありますが無料で使うことができます。
GCP無料枠についての詳細は「Google Cloud Platform の無料枠」から確認することができます。
Google reCAPTCHAの画像認証はユーザーに画像を用いた問題を出して人間かロボットかを判断するシステムです。
出典: HUNGRY APARTMENT.

上のやつがreCAPTCHAの画像認証です。
そしてVisionAPIは先ほど説明した通り画像に映っている人やモノ、テキストなどを分類したり特定したりできます。
**「あれ?このVisionAPI使えばreCAPTCHAの画像認証を自動で解決できそうだな」**と思ったので実際やってみました。
作ったもの
今回作ったのはreCAPTCHAから与えられた画像をVisionAPIに渡して結果を受け取るプログラム。
reCAPTCHAが「○○が写ってる画像をこの中から選んで!」と要求するのでVisionAPIに画像を渡せば「この部分に○○が写ってるよ!」と結果が返ってくるようにします。
その結果をもとにどのタイルをクリックするか決め、自動的にクリックするようにします。
環境はNode.jsでseleniumや@google-cloud/visionなどのモジュールを用いました。
作成の流れ
まず前提としてGCPのCloud Vision APIを有効にしています。APIキーの設定やChrome Driverのインストールは済ませてある状態です。
簡単に流れを説明するだけなので細かいことはいろいろ省きます。
SeleniumでChromeを起動する
Chromeをプログラムで自動操作するためにSeleniumを使いました。起動してreCAPTCHAをテストできるサイトにアクセスします。
seleniumモジュールをインポート
const webdriver = require("selenium-webdriver");
const { Builder, By, until } = webdriver;
ブラウザを起動してアクセス
const driver = await new Builder().withCapabilities(capabilities).build();
await driver.get('https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox-explicit.php');
await使う際はasync functionの中にコード書かないとエラーでるので注意。
reCAPTCHAのiframeから要素取得
reCAPTCHAはiframeで埋め込まれています。
まず自動でチェックボックスをクリックしないといけませんが、チェックボックス含むreCAPTCHAの要素はiframeの中にあるので要素を探す対象をiframeのドキュメントに切り替えないといけません。
iframe要素を探して切り替える
let iframe = await driver.findElement(By.tagName('iframe'));
await driver.switchTo().frame(iframe);
するとreCAPTCHAのチェックボックス要素を取得できるようになりました。
reCAPTCHAのチェックボックスを自動でクリックする
let checkBox = await driver.findElement(By.className('recaptcha-checkbox-border'));
await checkBox.click();
reCAPTCHAの画像と情報を取得する
reCAPTCHAが画像を使った認証を要求してくるのでその画像をまず取得します。リクエスト内容(お題)なども取得する必要があります。
しかしここでまた注意点があります。
reCAPTCHAの画像認証要素はまた別のiframe内にあります。
さっきiframeに移動してチェックボックスをクリックしましたが、その後に出現する画像認証ウィンドウみたいなやつは、それとはまた別のiframeの要素なのです。
なので、また要素を探す場所を切り替えないといけません。
一度親ドキュメント(defaultContent)に切り替え→画像認証のiframeに切り替え
await driver.switchTo().defaultContent();
let iframe = await driver.findElement(By.xpath("//iframe[@title='recaptcha challenge']"));
await driver.switchTo().frame(iframe);
タイルを取得
await driver.wait(until.elementLocated(By.className("rc-imageselect-tile")), 100000 /* timeout */);
let tiles = await driver.findElements(By.className("rc-imageselect-tile"));
画像認証は、画像が9分割されていたり16分割されていたりと変動するのでそのタイルを取得します。tilesには配列が代入されるのでtiles.lengthで分割数を確認できます。
お題を取得する
車を選択すればいいのか、自転車を選択すればいいのか、与えられたお題を取得します。
let desc;
try {
desc = await driver.findElement(By.className("rc-imageselect-desc-no-canonical"));
} catch(e) {
try {
desc = await driver.findElement(By.className("rc-imageselect-desc"));
} catch(e) {}
}
desc = await desc.getText();
const target = desc.split("\n")[1];
お題が表示される要素のクラス名がrc-imageselect-desc-no-canonicalとrc-imageselect-descで変動するのでtry&catchでなんとかしました。
画像を取得する
let tileSize = ~~Math.sqrt(tiles.length);
let image = await driver.findElement(By.className(`rc-image-tile-${"" + tileSize + tileSize}`));
let imageURL = await image.getAttribute('src');
タイルのクラス名もタイルの枚数(分割数)によって変動するので、このように対応しました。
これでreCAPTCHAから与えられた画像を取得することができました。
画像を分割する
さっそく取得した画像をVisionAPIに投げたいところですが、問題があります。
実はreCAPTCHAの画像ってこんなかんじになっています。

9つの画像が合わさって1つの画像になっています。
これをこのままVisionAPIに投げても、これがひとつの写真か何かと認識されるので上手く判断してくれません。
ということで画像を分割しないといけません。node.jsではsharpモジュールを使うことで自動で画像を切り抜きすることができます。
sharpで画像を切り抜きする
const sharp = require('sharp');
await sharp("./captcha_image.jpg").extract(
{
width: 100, //横幅
height: 100, //高さ
left: 0, //切り抜き開始地点x
top: 0 //切り抜き開始地点y
}
)
.toFile(`./0.jpg`)
.catch(function(err) {
console.log("Error.");
});
上記がsharpで画像を切り抜きするコードになります。これを実行すると9つのうち一番左上のタイル部分を切り抜きできます。0.jpgというファイル名で出力されます。
これを少しいじってループさせれば9つの画像にバラすことができます。
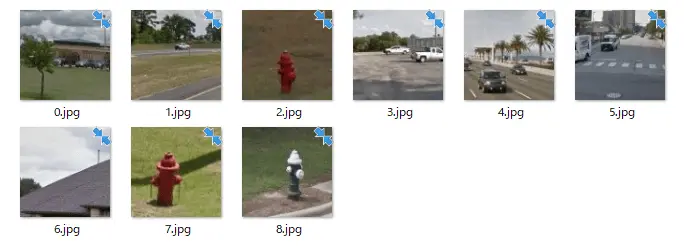
これでようやくVisionAPIに渡すことができます。
VisionAPIに渡して結果を検証
VisionAPIをNode.jsで使うにはモジュールと環境変数の設定が必要ですが、環境変数については省略します。
モジュール読み込んでクライアント呼ぶ
const vision = require("@google-cloud/vision");
const client = new vision.ImageAnnotatorClient();
リクエストをAPIに送って結果から正しい画像を選ぶ
const judge = {};
for (let i = 0; i < 9; i++) {
const request = {
image: {
content: fs.readFileSync(`./${i}.jpg`)
}
}
const [result] = await client.objectLocalization(request);
const res = result.localizedObjectAnnotations;
for (let j = 0; j < res.length; j++) {
console.log(i, "name:", res[j].name, "score:", res[j].score);
if (target.includes(res[j].name.toLowerCase())) judge[i] = true;
}
}
リクエストはobjectLocalization(request)で、結果はlocalizedObjectAnnotationsで受け取れます。リクエストには画像を添えます。
検証はめっちゃ雑ですww
受け取った結果のnameをすべて小文字に変換してreCAPTCHAのお題に同じ単語が含まれているか調べるだけです。
結果のnameはBicycleやFire hydrantというふうに画像に含まれるオブジェクトの名前になっているので割とこんな雑なやり方でも当たります(笑)
試してみよう
まずはreCAPTCHAの画像をVisionAPIがちゃんと識別できているかみてみましょう。
上の画像を使って書いたプログラムをテストしてみます。結果は以下のようになりました。
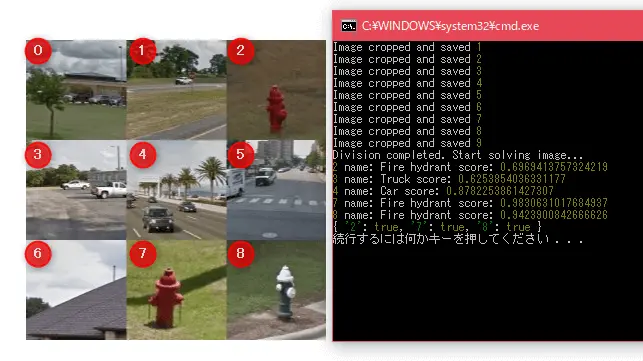
お題が「a fire hydrant」つまり消火栓です。消火栓は目視でみたかんじだと2番, 7番, 8番ですよね。
VisionAPIの結果から予測した番号と同じになっています。つまり成功です。
自動でタイルを選択し送信
あとは結果をもとにタイルをクリックして認証ボタンを押すだけです。
let te = await driver.findElements(By.className("rc-imageselect-tile"));
for (let i = 0; i < tiles.length; i++) {
if (judgeResult[i]) te[i].click();
}
さきほどと同様にタイル要素を取得して検証結果(オブジェクト)をもとにクリックさせます。
あとは認証ボタンを押すだけ。
let verify = await this.driver.findElement(By.id("recaptcha-verify-button"));
await verify.click();
これで完了です。あとは追加認証がなければ無事にreCAPTCHA突破です。
動画(いろいろ問題ある)
今回書いたプログラムを実際に動作させている様子をキャプチャしました。
これが現実ですね・・・。正確に選ぶことができていますが、「一度の認証で済むと思うなよ!」と追加で認証を要求されてしまいました。
reCAPTCHA突破はそう簡単にはいかないみたいです。
ですが、今回VisionAPIでかなり正確に画像を識別できることがわかったので他のことにも応用できそうです。
最後まで読んでいただきありがとうございました。


